线程泄露引发一系列问题排查
CosClient 使用后未关闭引发线程泄露,导致 skywalking 采集线程长期占用大量 CPU,大量请求超时,网络IO被中断
背景
我们的服务部署在云上,部署了多台 pod,对应的工作负载配置了 k8s 存活探针(走 http 协议),当 k8s 检测到 pod 中服务不可用时,会自动重启 pod,并通知到开发人员。
问题
- 服务上线后,有时会无缘无故重启,到 pod 上也找不到报错日志,能从 k8s 日志上找到是健康检查没有通过,导致服务重启
- 服务在稳定运行一段时间后,会变得卡顿,请求超时,导致客户吐槽
排查过程
在一次值班时,我收到了服务重启通知,分别登录到被重启的 pod (代号 A )和未被重启的 pod (代号B),A 已经被重启了,短时间内问题肯定不会复现,B没有被重启,并且启动时间和 A 上一次启动时间一样,所以 B 很有可能会再次重启,在 B 重启前,我们必须定位到问题点。以下是问题排查过程
1. 找到对应的进程,查看进程中线程运行情况
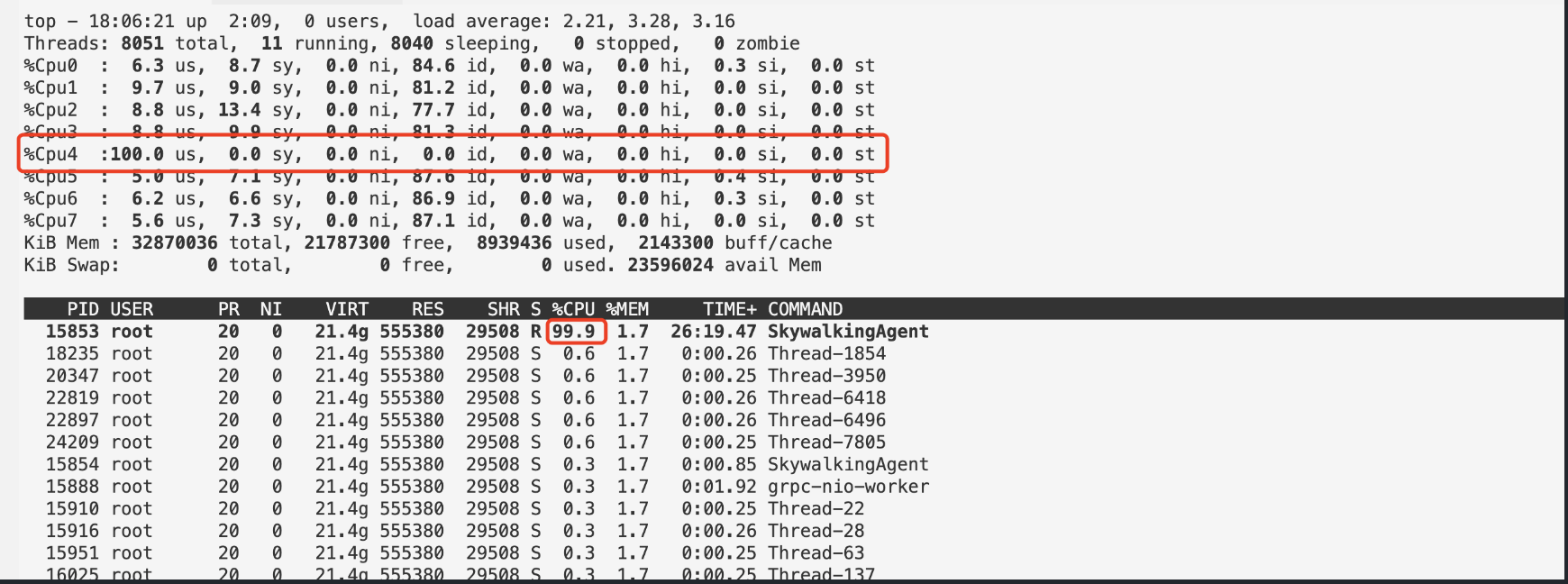
使用top -H -p ${pid} 持续观察线程的运行情况,发现 skywalking-agent 线程持续高占用 cpu
2. 使用 arthas 在线排查 skywalking-agent 线程正在进行的操作
进入 arthas 后输入 thread -n 3 查看 cpu 占比前三的线程,并且重复几遍,观察到 SkywalkingAgent-5-JVMService-produce-0 (即 skywalking-agent )线程一直在采集线程统计信息,并且占用大量 cpu ,从 skywalking 源码 中看到,该采集线程每秒调用一次,统计线程数量,到这里就可以定位到大概率是和线程数有关。
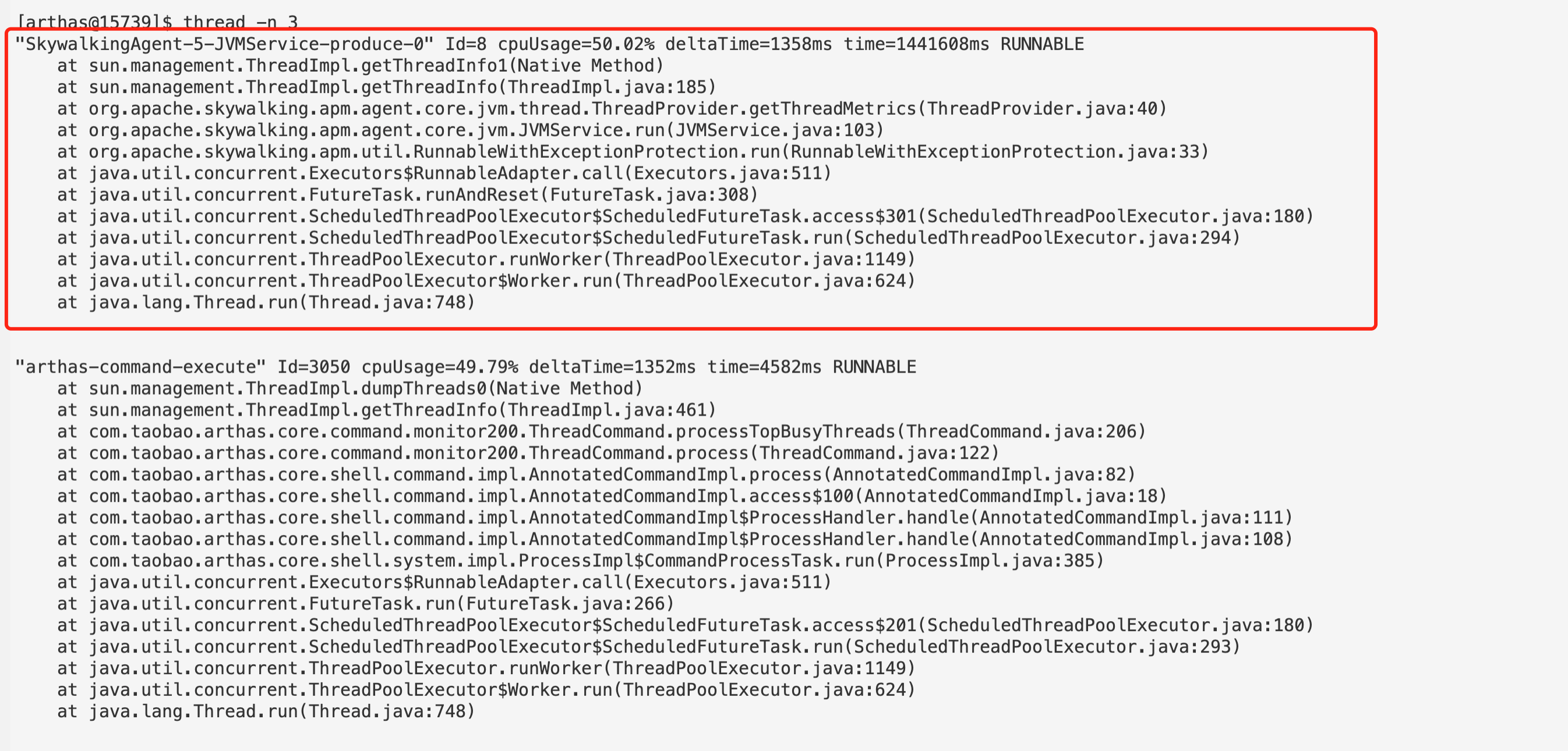
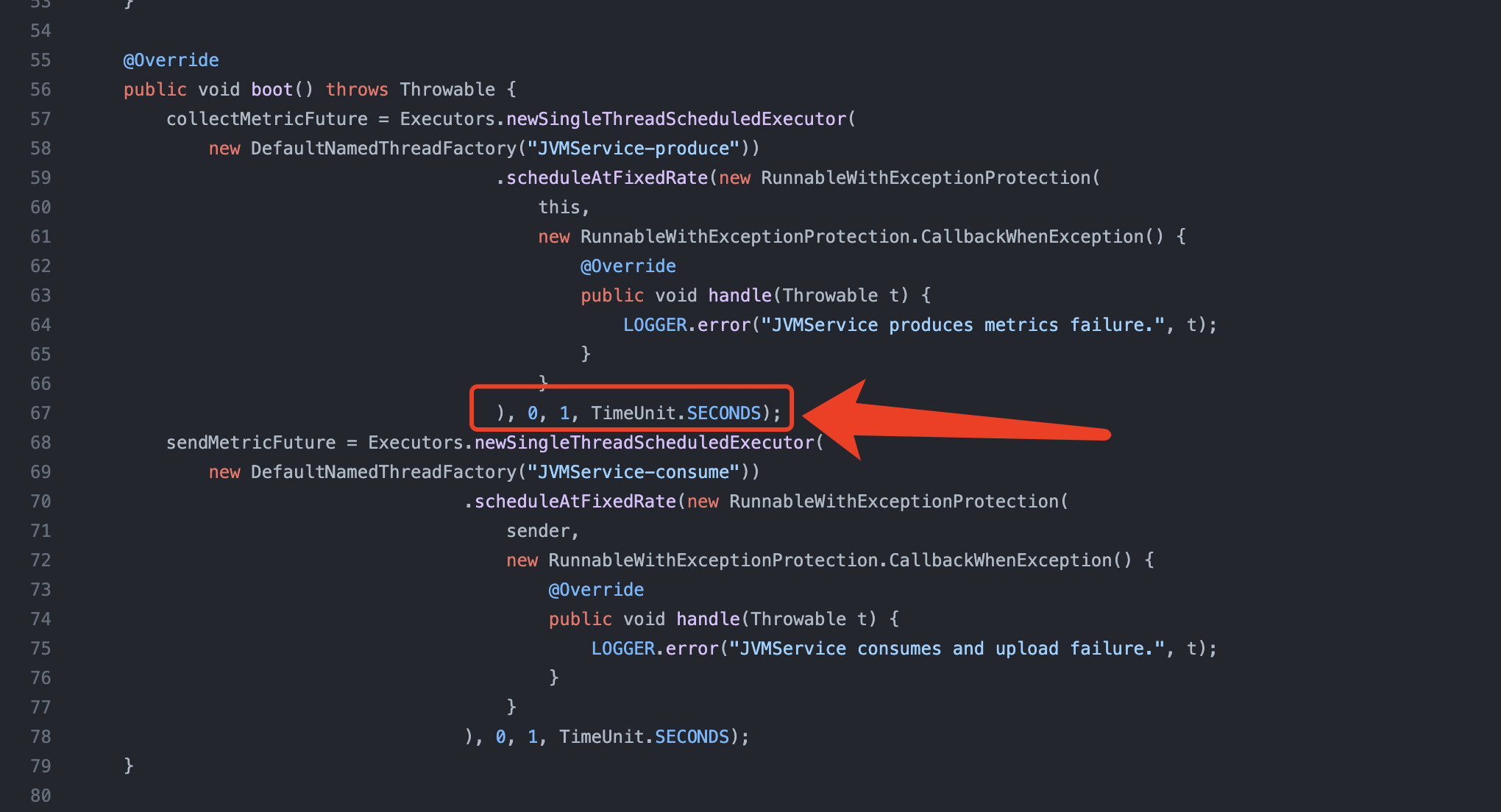
3. 开发模拟线程数程序
开发线程数模拟程序的目的是验证线程数逐步提高的过程中,skywalking-agent 采集线程对 cpu 的占用是否越来越高。
从观察到的现象来看,当线程数稳定在 3025 时,skywalking-agent 采集线程占比为 16.1%,当线程数稳定在 8035 时,skywalking-agent 采集线程占比为 99.9%,到此能确认线程数会影响 skywalking-agent 采集线程对 cpu 的开销,并且是正相关。
模拟过程为
- 启动线程数模拟程序时接入 skywalking(启动过程中指定 javaagent 即可)
- 程序启动后使用
top -H -p ${pid}持续观察 skywalking-agent 采集线程对 cpu 的占比
从模拟程序来看,只有存在大量线程时,skywalking-agent 采集线程占比才会越来越高,我们模拟的程序最高有 8K 个线程,这个线程数已经远远超过了单个服务常规线程数
4. 观察生产环境线程
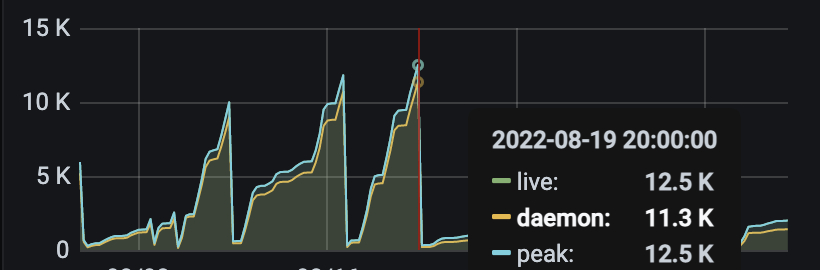
服务引入了 pushgateway 来监控服务,能在 grafana 上观察到,线程数一直在涨,最高达到 12K,并且大部分现场都是在等待状态,这个情况存在异常。
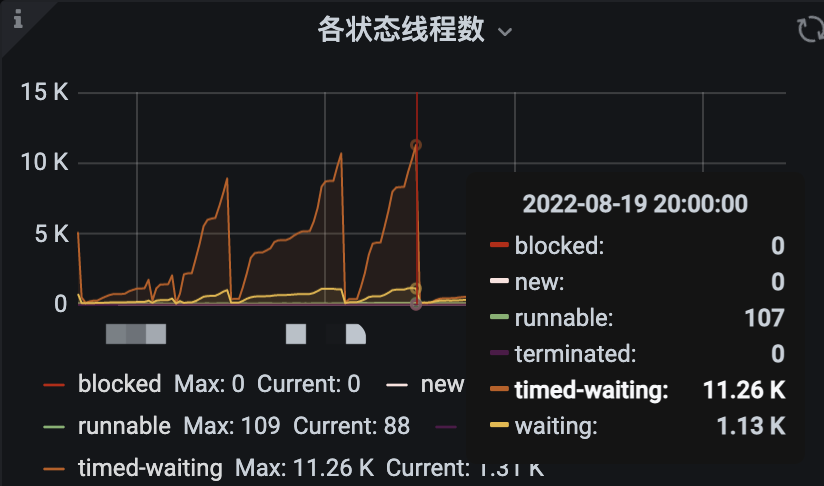
5. 定位到线程泄露
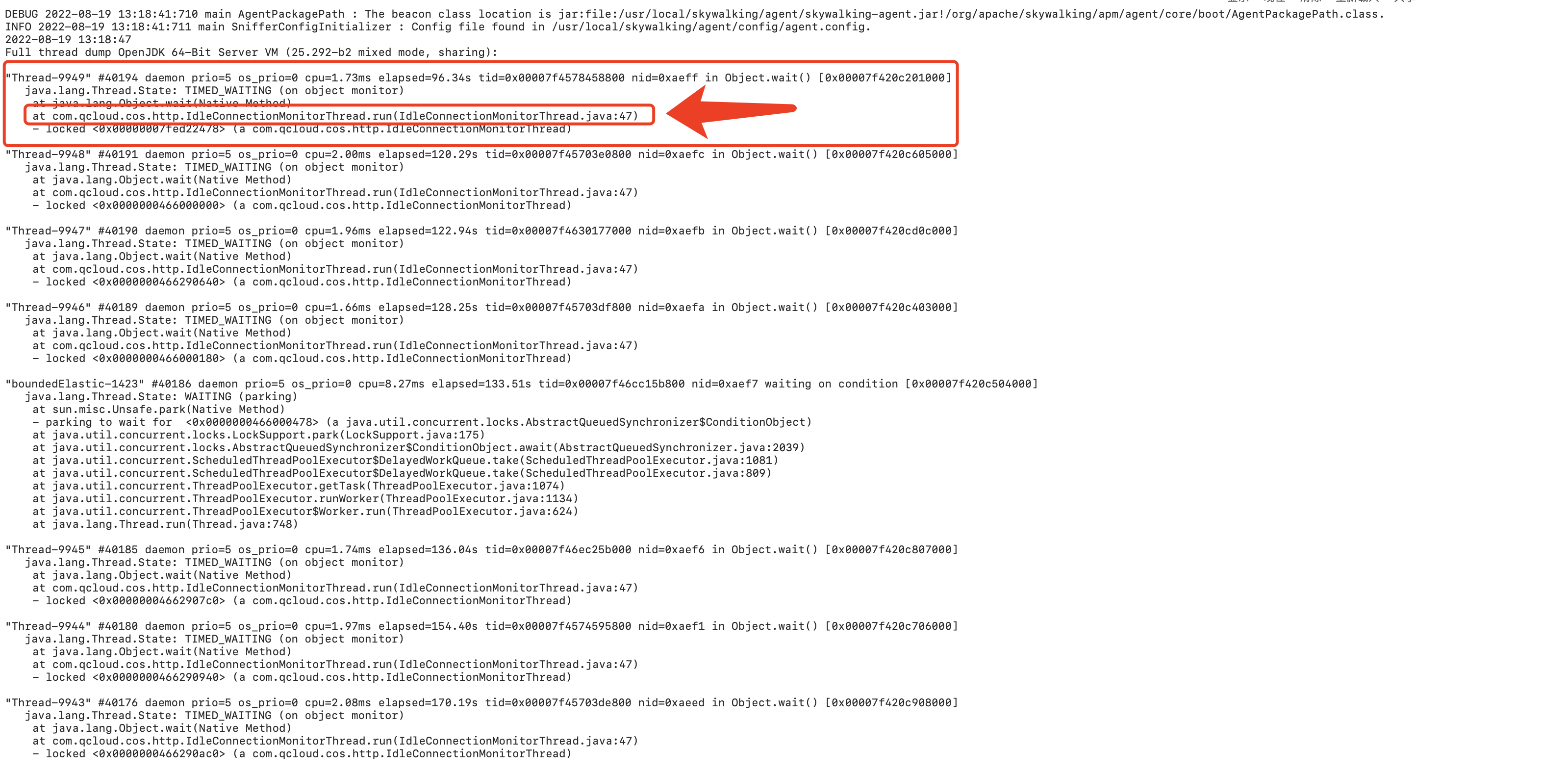
在 Pod B 中使用 jstack ${pid} > jstack_thread.log 导出服务中所有的线程,从导出的文件中观察到,存在大量的 IdleConnectionMonitorThread 线程正在运行,从源码代码中可以看到,启动 CosClient 会启动该线程,并且业务代码中使用完之后没有关闭 CosClient,导致线程泄露。
总结及解决方案
该问题是使用 CosClient 后未关闭导致的线程泄露,导致 skywalking-agent 采集频率高,当线程数超过了机器正常调度的线程数时,会会导致服务卡顿,大面积请求超时(tomcat一个请求一个线程),网络IO被中断。排查过程中同样也暴露出另外一个问题,skywalking 采集线程采集的频率太高,每秒采集一次,并且不能配置,已经在 Skywalking 社区发起讨论。当前的解决方案如下
- 短期内先下掉 skywalking,避免长时间高占用 CPU
- 检查所有业务代码,所有使用了 CosClient 的地方均需要关闭,并且进行充分验证回归